k均值聚类算法
牧师-村民模型
先讲一个故事:有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课。听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海报上更新了自己的布道点的位置。牧师每一次移动不可能离所有人都更近,有的人发现A牧师移动以后自己还不如去B牧师处听课更近,于是每个村民又去了离自己最近的布道点……就这样,牧师每个礼拜更新自己的位置,村民根据自己的情况选择布道点,最终稳定了下来。 这个故事中村民根据实际情况选择牧师的过程就是k均值聚类的过程,其中村民代表样本,牧师代表某类样本的中心点。
# k均值聚类算法介绍 均值(k-means)算法,K代表的是K类,Means代表的是中心,算法的本质是设定K个中心点,然后不断的调整这k个类别的边界和中心,当你找到了这些中心点,也就完成了聚类。那么如何确定K类的中心点呢?一开始我们是可以随机指派的,当你确认了中心点后,就可以按照距离将其他样本划分到不同的类别中。
# 算法基本流程
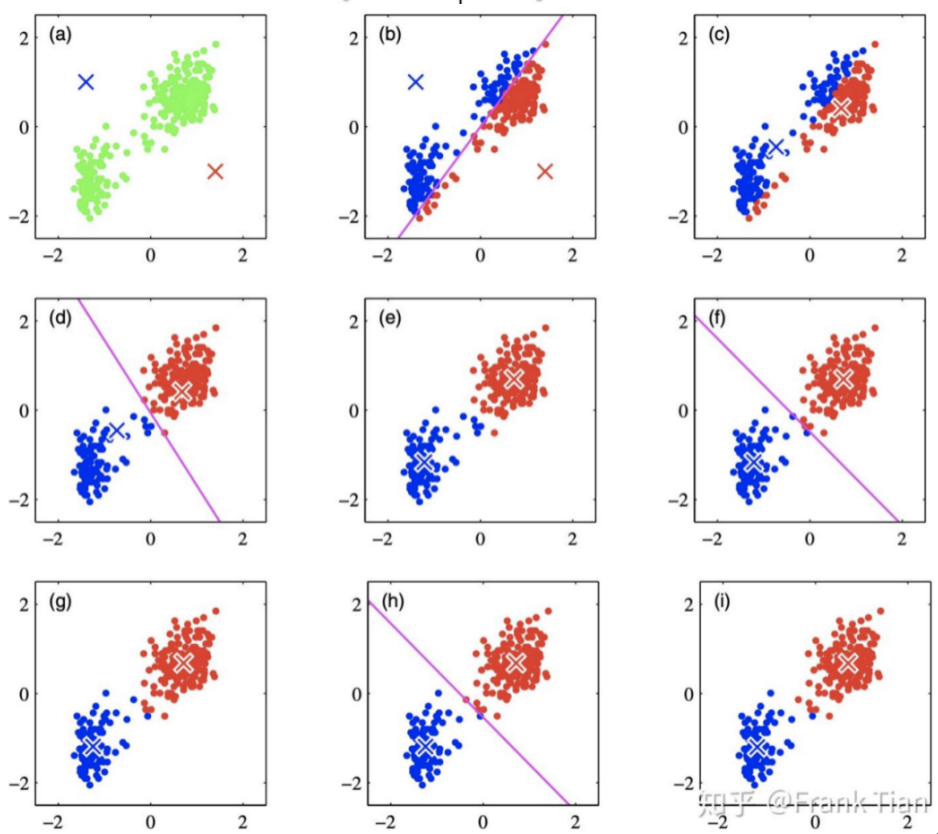
- 选取K个点作为初始聚类中心点$a=a_1,a_2,…,a_k$,一般都是从数据集中随机抽取;
- 针对数据集中每个样本计算它到K个聚类中心的距离(一般用欧式距离)并将其分到距离最近的聚类中心所对应的类中,这样就形成了K个类;
- 然后针对每个类别,重新计算每个类的中心点(计算每个类的中心点,每个维度的平均值就可以的); \(a_{j}=\frac{1}{\left|c_{i}\right|} \sum_{x \in c_{i}} x\)
- 重复第2、3步,直到达到某个中止条件(达到最大迭代次数、最小误差变化等)。
# 代码 https://github.com/mubaris/friendly-fortnight
# 演示 这个demo需要在Java环境下运行,我还没试过。 http://home.deib.polimi.it/matteucc/Clustering/tutorial_html/AppletKM.html