2020/4/22华为机试-报文校验
今天做了一道华为机试的题目,分享下我的做法。
第二题:题目描述
某协议T报文格式如下(以下数据都以16进制描述):
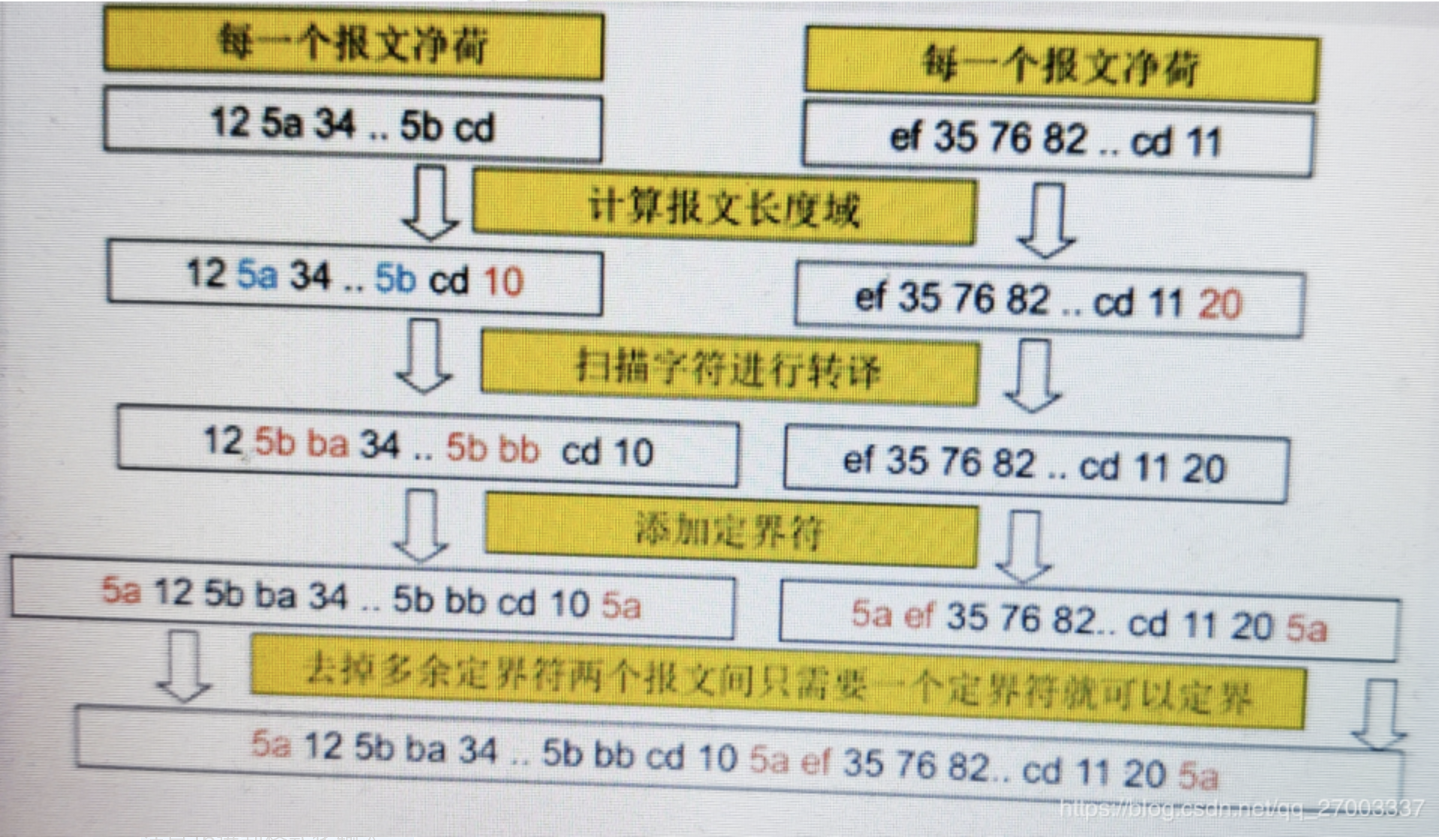
- 每一个T报文以5a开头,以5a结尾,即开始符和结束符都为5a.
- 每个T报文在结尾前有1个字节的长度域,指示报文净荷的长度(不含开始符、结束符、长度域)。
- T报文中如果出现5a字符,转义成为5b ba。如果出现5b字符,转义成为5b bb.
- 转义过程不影响长度域,或者说长度域是报文转义前的净荷长度。 两个T报文间由5a划分,即两个连续T报文间只需要一个 开始/结束符。 正常数据流都是由大量的T报文经过下面的流程生成,下图示例中第一个报文中含有需要转码的5a和5b数据,第二个报文没有需要转码的数据。但本题测试数据中有些报文可能未完全按照上面的要求正确生成。
编程要求:
- 检查报文是否满足T报文格式要求,包括开始符、结束符、转义符,并进行长度校验。
- 将满足T报文格式且通过长度校验的正确报文输出到output文件。
- 每一个报文在文件中的先后顺序不能改变,只过滤掉校验不过的报文。
- 编程语言不限
输入描述
一组按上述流程生成的T报文数据,其中部分报文可能存在错误,报文数据的数据类型都为1 6进制的整数,中间用空格隔开。 注意16进制格式化输入。
输出描述:
经过校验和过滤的报文流,报文数据的数据类型都为1 6进制的整数,中间用空格隔开。 注意格式化输出,每个数据(即每个字节)要按两个字符的格式输出,单字符数字前面补’0’,(如’6’要输出为’06’)。
输入
5a 12 5b ba 34 5b bb 88 05 5a 75 cd bb 62 5a 34 cd 78 cc da fb 06 5a
输出
5a 12 5b ba 34 5b bb 88 05 5a 34 cd 78 cc da fb 06 5a
说明
输入样例中间的报文长度域错误,不能通过校验算法,第一和第三个报文能够通过校验算法 。
my_str = '5a 12 5b ba 34 5b bb 88 05 5a 75 cd bb 62 5a 34 cd 78 cc da fb 06 5a '
my_str = my_str.split('5a')
after_str = '5a'
for i in range(1, len(my_str) - 2):
longth = 0
my_str_split = my_str[i].split(' ')
for j in range(1,len(my_str_split)-1):
if ((my_str_split[j] == '5b') and (my_str_split[j + 1] == 'ba')) or ((my_str_split[j] == '5b') and (my_str_split[j + 1] == 'bb')):
longth = longth + 1
x = int(my_str_split[-2])
if (len(my_str_split) - 3 - longth) != x:
my_str.pop(i)
after_str = after_str + my_str[i] + '5a'
print(after_str)